DETR End-to-End Object Detection with Transformers
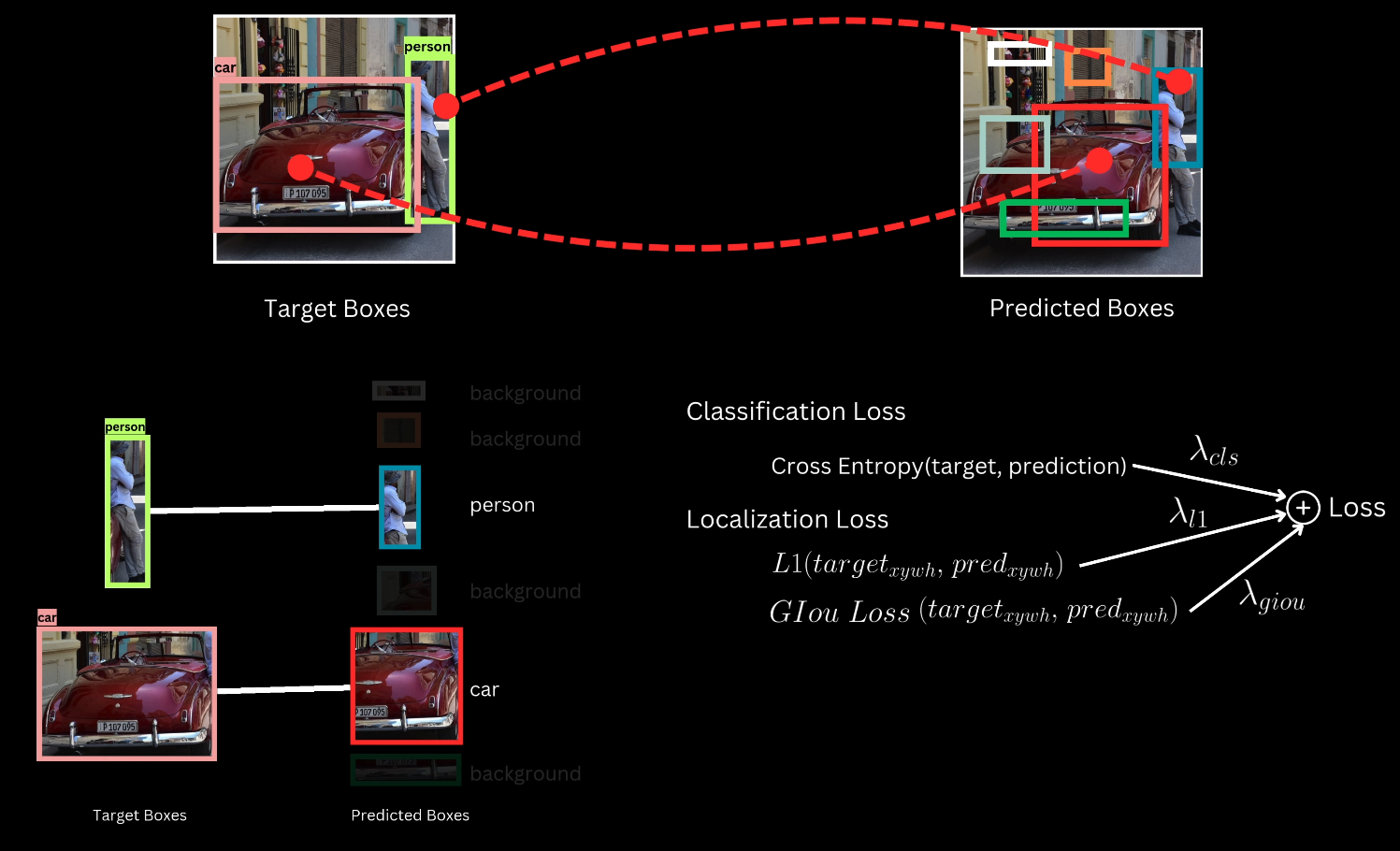
DETR Architecture Components Backbone for Feature Extraction The initial input image is processed by a backbone, typically a pre-trained Convolutional Neural Network (CNN), such as ResNet 50 or ResNet 101, trained on the ImageNet classification task. The last pooling and classification layers are discarded to produce a feature map that captures semantic information for different regions of the image. The network stride is typically 32. The feature map output dimensions are $C \times \text{feature map height} \times \text{feature map width}$, where $C$ is the number of output channels of the last convolution layer. ...